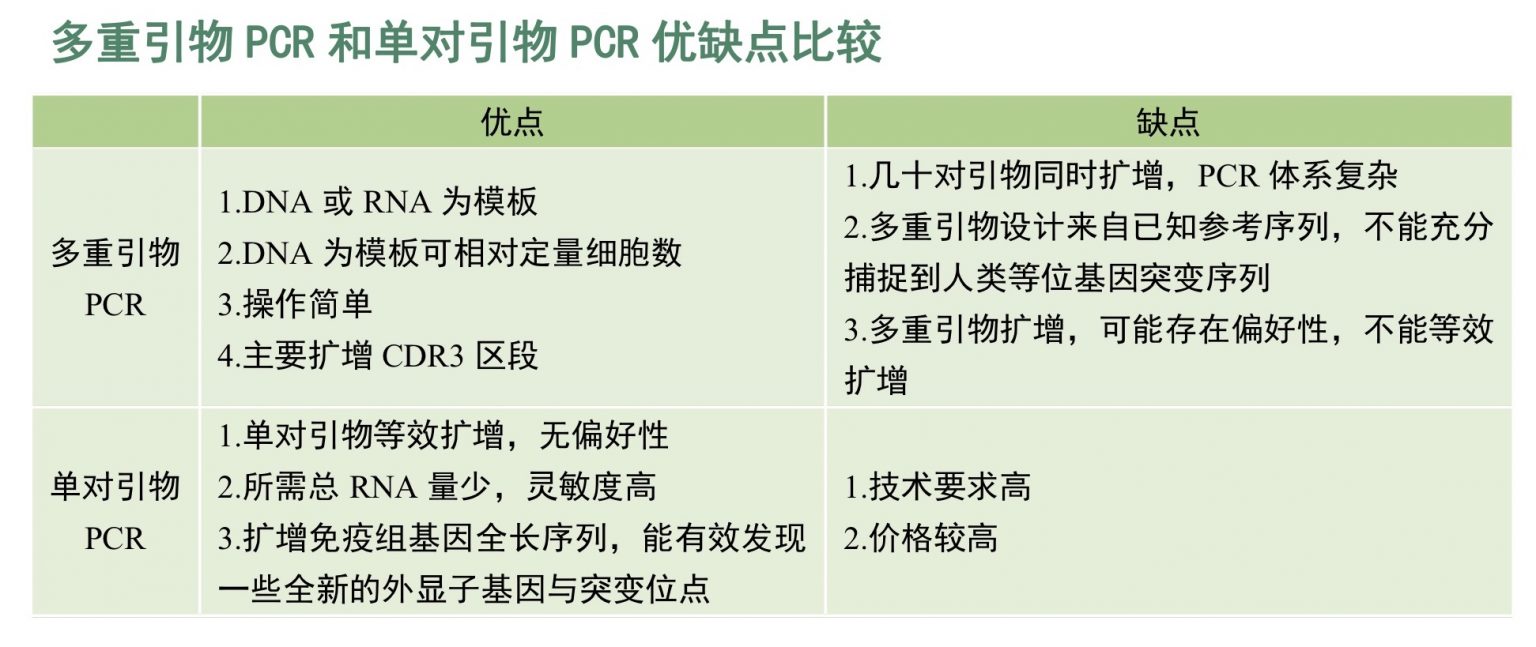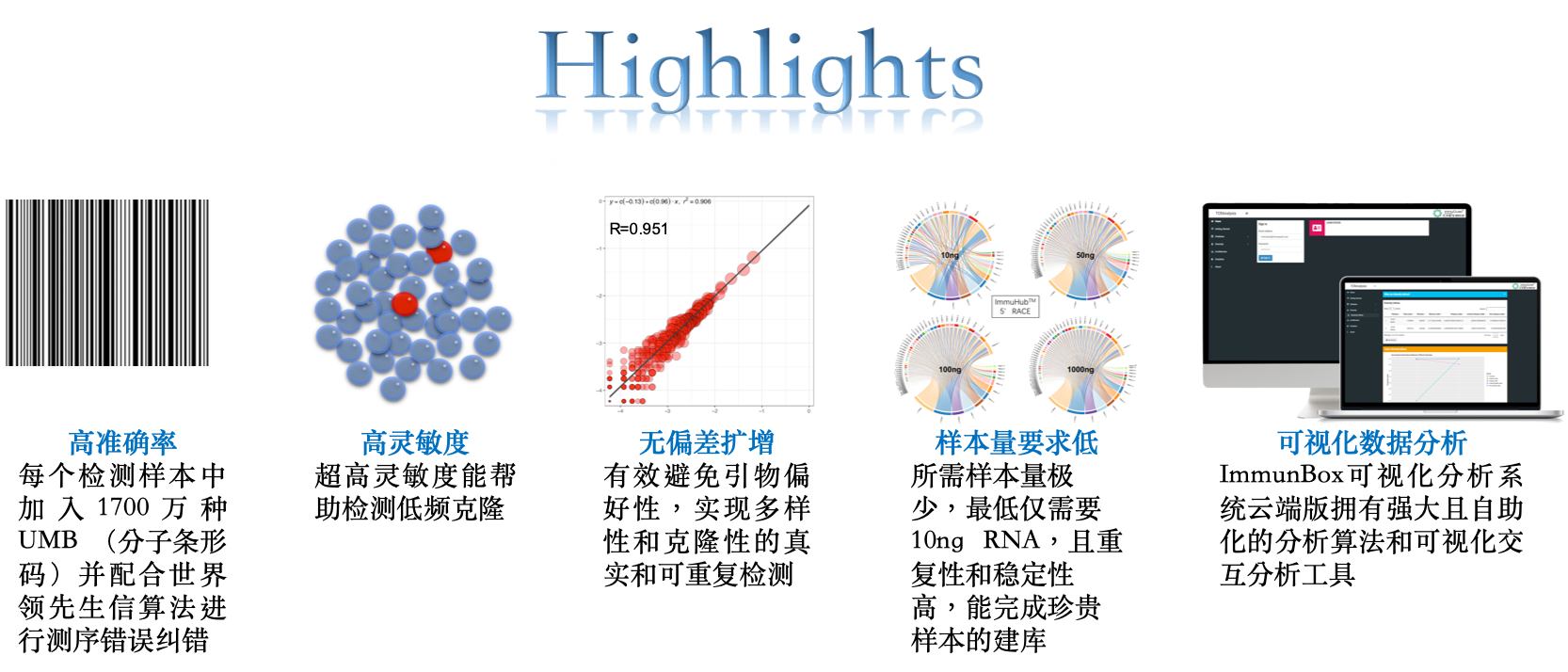
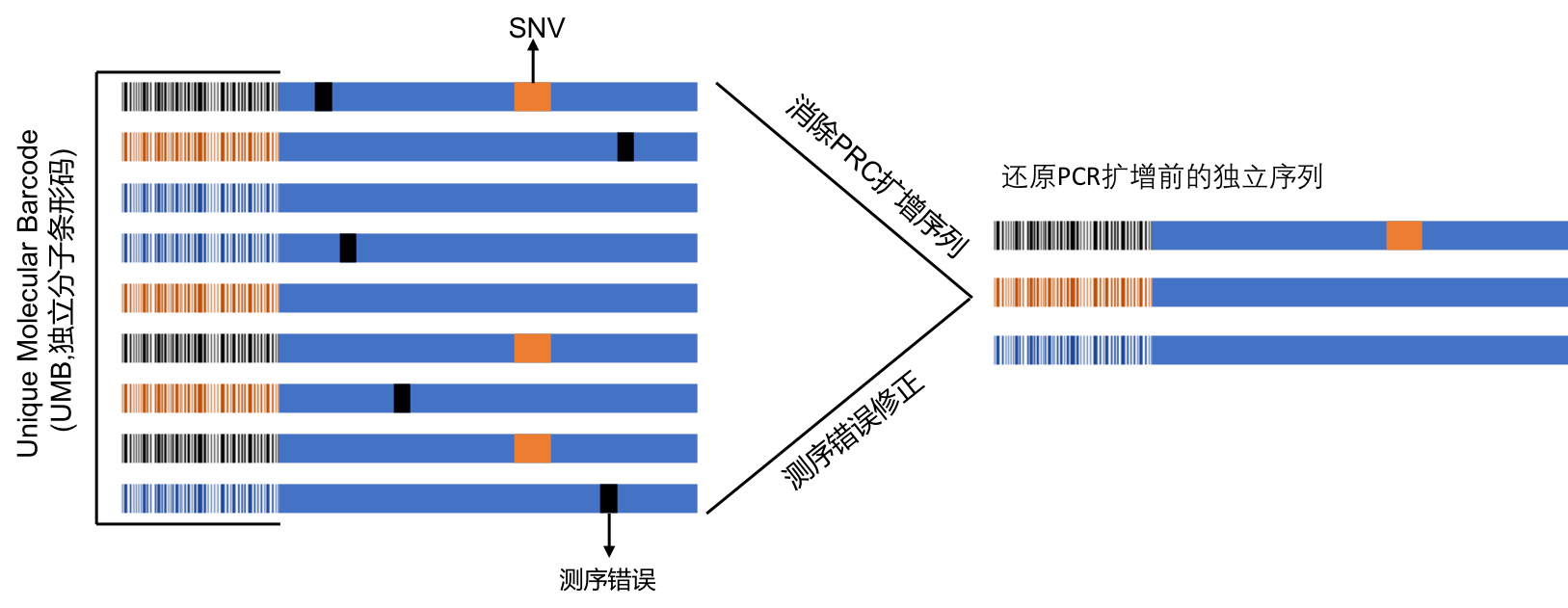
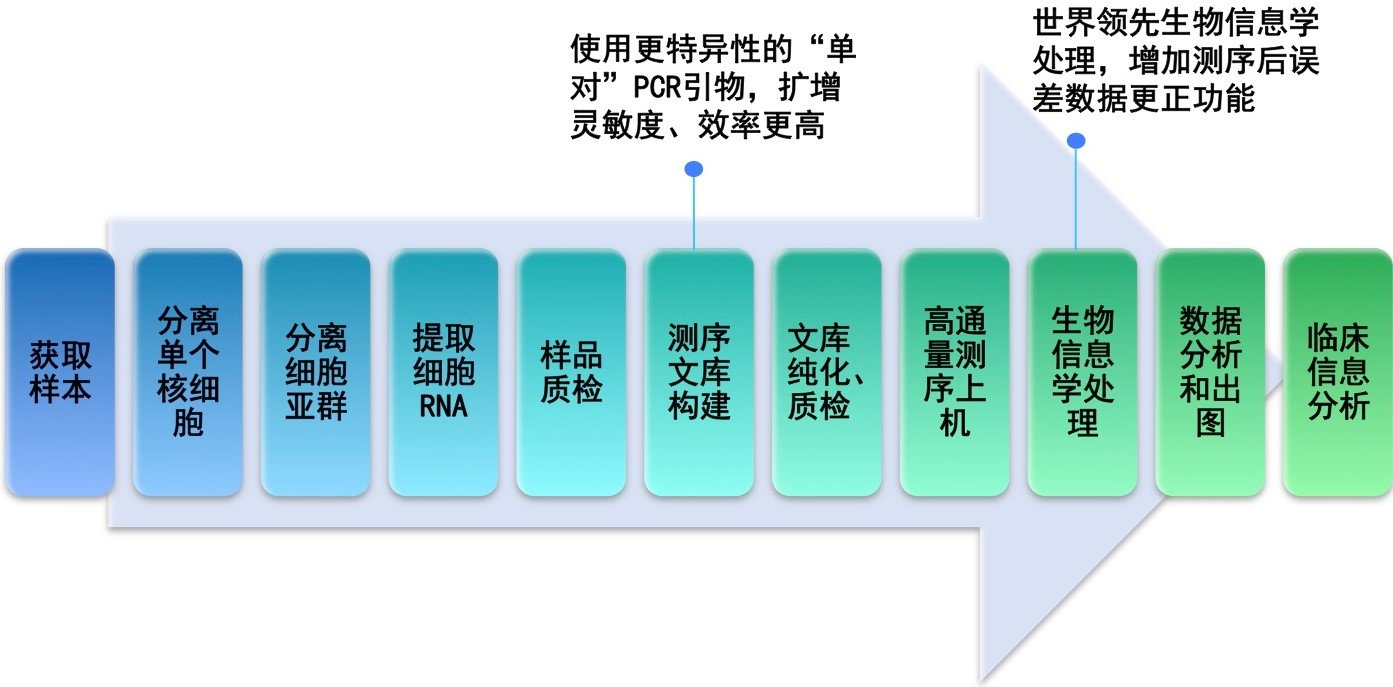
服务流程:客户提供样本,通常为全血、骨髓、单个核细胞、分离后的T、B细胞、RNA/cDNA或者石蜡包埋的组织[FFPE],送达公司实验室后,实验室根据样本的情况,进行血液或骨髓的T/B细胞分离→ RNA 提取→ cDNA 合成→测序文库构建→第二代基因测序→生物信息学处理→数据分析和出图→临床信息分析(如下图)。 45个工作日后客户获得测序结果报告。
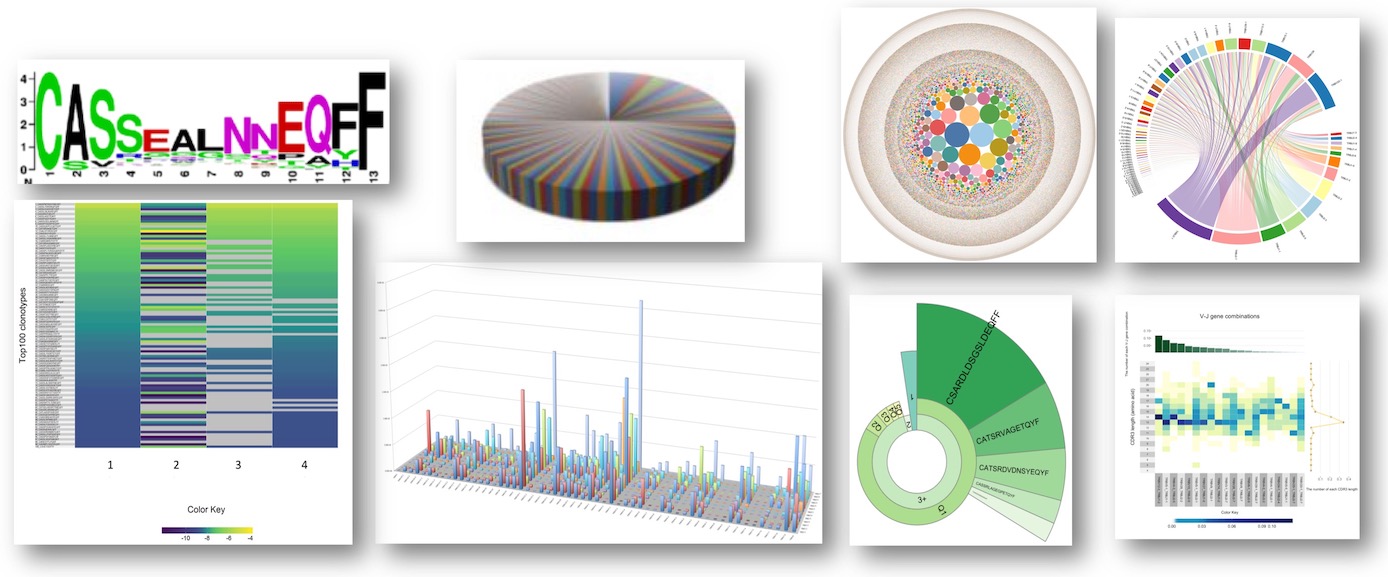
状态的统计、总结、谱系等
- 计算样本的统计总结:序列读数、平均克隆种类大小,无功能克隆种类数等
- 计算样本每个V和J基因的使用率,绘制基于标准分数(z-Score)的热力图(heatmap)
- 计算CDR3克隆种类长度的高斯分布,绘制前N个最高表达CDR3克隆的谱系图
- 绘制V-J基因配对频率图、3D森林图
- 基于CDR3基因长度,计算和绘制V基因的分布图
样本多态性和克隆性评价
- 计算、比较样本间多样性和克隆性 (计算 Shannon、Simpson、Berger-Parker指数)
- 绘制样本多态性、克隆性图谱
![]()
![]() 样本间克隆种类重合、共享分析 (overlap and sharing)
样本间克隆种类重合、共享分析 (overlap and sharing)
- 计算两个样本克隆种类的共享情况,追踪同一个病人治疗前后某个克隆种类变化
- 绘制两个样本间克隆种类配对比较图
我们也将按照客户的要求提供更多的分析和不同的数据报告形式,数据结果将以电子文档的形式传送给客户