

еЉХи®А
дњ°жБѓжКАжЬѓеТМињРзЃЧйАЯеЇ¶зЪДењЂйАЯеПСе±ХпЉМжО®еК®дЇЖдЇЇеЈ•жЩЇиГљз≠ЙзГ≠йЧ®жКАжЬѓеПЦеЊЧз™Бз†ігАВеРМжЧґпЉМйЪПзЭАеМїзЦЧи°МдЄЪзЪДдњ°жБѓеМЦпЉМдЇІзФЯзЪДеМїзЦЧжХ∞жНЃиґКжЭ•иґКе§ЪгАВе¶ВдљХе∞ЖеМїе≠¶жХ∞жНЃеТМдЄНжЦ≠еПСе±ХзЪДдЇЇеЈ•жЩЇиГљжКАжЬѓеЇФзФ®дЇОзЦЊзЧЕйҐДйШ≤гАБж£АжµЛеТМеМїзЦЧдњЭеБ•з≠ЙйЧЃйҐШдЇЯеЊЕиІ£еЖ≥пЉМе∞§еЕґзФ®дЇОеЫЮз≠ФеМїе≠¶йЧЃйҐШжШѓељУеЙНз†Фз©ґзЪДдЄАе§ІзГ≠зВєгАВ
дЄОж≠§еРМжЧґпЉМеМїе≠¶з†Фз©ґеЈ≤еЉАеІЛдїОдЉ†зїЯзЪДзЦЊзЧЕйҐДйШ≤иљђеРСзїЖиГЮеТМеЯЇеЫ†жЦєйЭҐпЉМеѓїж±ВзЦЊзЧЕжґИзБ≠зЪДж†єжЬђеОЯеЫ†гАВжЬЇеЩ®е≠¶дє†зЃЧж≥ХеЈ≤еєњж≥ЫеЇФзФ®дЇОеРДзІНеЇФзФ®еТМеМїе≠¶з†Фз©ґгАВиЩљзДґзЃЧж≥ХзІНз±їзєБе§ЪпЉМдљЖзЫЃеЙНдљњзФ®зЪДдЄїи¶БзЃЧж≥ХдїНжШѓдЉ†зїЯзЃЧж≥ХпЉМе¶ВйЪПжЬЇж£ЃжЮЧгАБйАїиЊСеЫЮељТз≠ЙпЉМдї•еПКжФѓжМБеРСйЗПжЬЇпЉМдїЦдїђйГљжЬЙдЄАдЄ™еЕЕеИЖзЪДзРЖиЃЇгАВзДґиАМпЉМдЄНе≠ШеЬ®еѓєжЙАжЬЙзЪДзЦЊзЧЕйГљдЄЇжЬАдЉШзЪДзЃЧж≥ХпЉМйТИеѓєдЄНеРМзЪДзЦЊзЧЕйЬАи¶БдљњзФ®дЄНеРМзЪДзЃЧж≥ХгАВ
еЈ®зїЖиГЮзЧЕжѓТпЉИCytomegalovirus, CMVпЉЙжШѓдЄАзІНеЬ®дЇЇзЊ§дЄ≠жДЯжЯУйЭЮеЄЄеєњж≥ЫзЪДзЦ±зЦєзЧЕжѓТпЉМеЬ®дЄ≠еЫљжИРеєідЇЇдЄ≠жДЯжЯУзОЗиґЕињЗ95%гАВеИЭжђ°жДЯжЯУеРОпЉМCMVеЬ®еЃњдЄїзїЖиГЮеЖЕе§ДдЇОзїИзФЯжљЬдЉПзКґжАБпЉМеєґеЬ®еКЯиГљжАІеЕНзЦЂз≥їзїЯи∞ГжОІдЄЛе§ДдЇОеС®жЬЯжАІдЇЪдЄіеЇКеЖНжњАжіїзКґжАБгАВељУдЄ•йЗНеЕНзЦЂеКЯиГљзЉЇйЩЈзЪДжВ£иАЕеПСзФЯеЖНжњАжіїжИЦеОЯеПСжАІжДЯжЯУжЧґпЉМеѓЉиЗіCMVе§Неȴ姱жОІеЗЇзО∞еПСзГ≠гАБй™®йЂУжКСеИґеТМзїДзїЗдЊµиҐ≠жАІзЦЊзЧЕзЪДдЄіеЇКи°®зО∞гАВеЫ†ж≠§гАВиѓКжЦ≠жВ£иАЕзЪДCMVжЪійЬ≤еП≤еЕЈжЬЙиЊГе§ІзЪДз†Фз©ґжДПдєЙгАВ
еЬ®жЬђз†Фз©ґдЄ≠дї•CMVжДЯжЯУдљЬдЄЇж®°еЮЛпЉМжИСдїђжПРеЗЇдЇЖдЄАзІНйАЪињЗTзїЖиГЮеПЧдљУќ≤йУЊпЉИTCRќ≤пЉЙйЂШйАЪйЗПжµЛеЇПзїУжЮЬжЭ•ж£АжµЛзЦЊзЧЕзКґжАБзЪДжЦ∞жЦєж≥ХгАВ
зїУжЮЬ¬†
CMVзЫЄеЕ≥TCRsзЪДйЙіеЃЪ
Fisherз≤Њз°Ѓж£Ай™МпЉЪеЯЇдЇОиЃ≠зїГж†ЈжЬђйШЯеИЧ1дЄ≠пЉМжѓПдЄ™CMVзЫЄеЕ≥TCRќ≤еЬ®жѓПдЄ™йШ≥жАІгАБйШіжАІж†ЈжЬђдЄ≠еЗЇзО∞зЪДж†ЈжЬђжХ∞пЉМдї•еПКж≤°жЬЙиѓ•еЇПеИЧжХ∞жНЃзЪДж†ЈжЬђжХ∞пЉМеїЇзЂЛжѓПдЄ™еЇПеИЧзЪДжЈЈжЈЖзЯ©йШµпЉМиЃ°зЃЧFisherз≤Њз°Ѓж£Ай™МзЪДpеАЉгАВеЫ†ж≠§пЉМFisherз≤Њз°Ѓж£Ай™МеЊЧеИ∞зЪДзЫЄеЕ≥еЇПеИЧдїЕдЄОйШЯеИЧ1зЪДиЃ≠зїГжХ∞жНЃзЫЄеЕ≥пЉМдЄОйШЯеИЧ2зЪДжµЛиѓХжХ∞жНЃж≤°жЬЙзЫіжО•зЫЄеЕ≥жАІгАВ
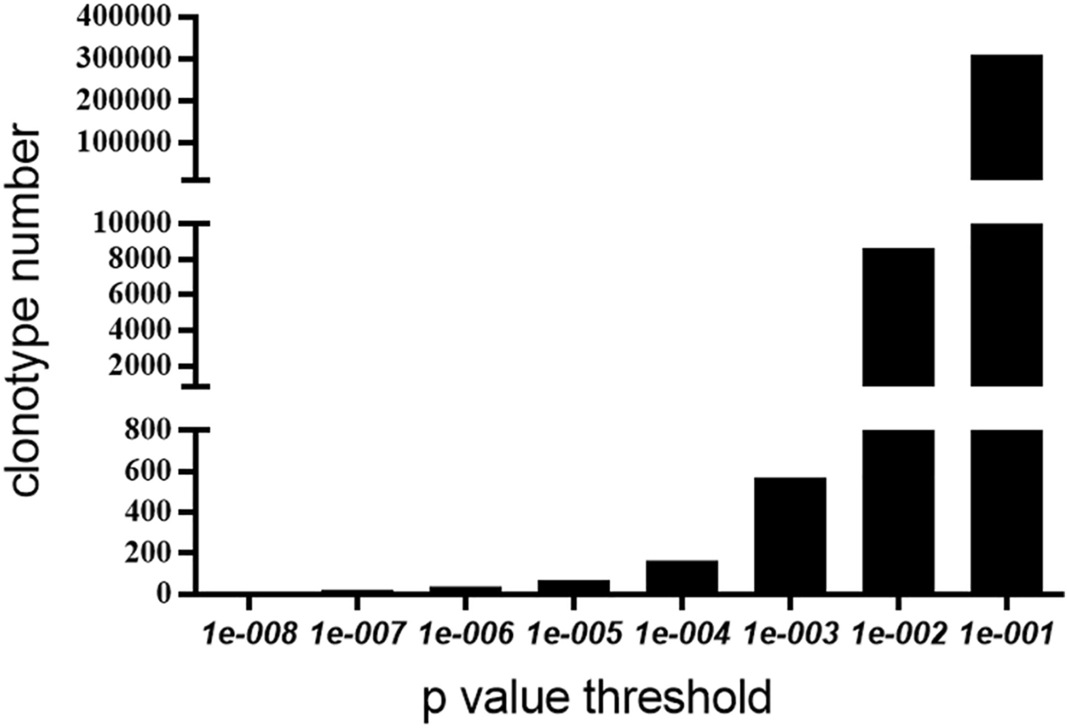
зїУжЮЬ¬†
LDAзЪДpеАЉзЪДжЬАдљ≥жИ™жЦ≠еАЉдЄЇ10^-4пЉМLRгАБSVMеТМRFзЪДpеАЉзЪДжЬАдљ≥жИ™жЦ≠еАЉдЄЇ10^-5
еЫЊ2жППињ∞дЇЖеЫЫзІНзЃЧж≥ХзЪДеИЖз±їжЬЙжХИжАІжМЗж†ЗзЪДжАІиГљпЉМжµЛйЗПдЇЖеЫЫзІНеИЖз±їзЃЧж≥ХзЪДжХ∞жНЃгАВxиљіи°®з§ЇPеАЉзЪДдЄНеРМйШИеАЉпЉМyиљіи°®з§ЇеѓєеЇФдЄНеРМйШИеАЉзЪДеЫЫзІНзЃЧж≥ХзЪДиѓДдїЈжМЗж†ЗгАВе¶ВеЫЊ2aжЙАз§ЇпЉМLR logisticеЫЮељТзЃЧж≥ХзЪДF1еЊЧеИЖйЪПйШИеАЉзЪДеҐЮеК†еСИзО∞еЕИдЄКеНЗеРОдЄЛйЩНзЪДиґЛеКњпЉМеЬ®йШИеАЉдЄЇ10^-4гАБ10^-5еТМ10^-6жЧґе§ДдЇОиЊГйЂШж∞іеє≥гАВељУйШИеАЉеҐЮе§ІжЧґпЉМAUCеАЉеЕИеҐЮе§ІеРОйЪПйШИеАЉзЪДеҐЮе§ІиАМеЗПе∞ПпЉМеЬ®йШИеАЉдЄЇ10^-3гАБ10^-4гАБ10^-5жЧґAUCеАЉиЊГйЂШпЉМеЬ®10^-4жЧґAUCеАЉжЬАйЂШгАВFDRйФЩиѓѓеПСзО∞зОЗйЪПйШИеАЉзЪДеҐЮе§ІеЕИеЗПе∞ПеРОеҐЮе§ІпЉМеЬ®10^-5жЧґжЬАдљОгАВдЇ§еПЙзЖµжНЯ姱еЗљжХ∞йЪПжЧґйЧізЪДеҐЮеК†еЕИзЉУжЕҐеЗПе∞ПеРОињЕйАЯеҐЮе§ІпЉМжЬАдљОзВєжШѓеЬ®10^-4пЉМзђђдЇМдЄ™жШѓ10^-5гАВдїОеЫЊ2bдЄ≠еПѓдї•зЬЛеЗЇпЉМSVMзЃЧж≥ХзЪДF1иѓДеИЖйЪПзЭАйШИеАЉзЪДеҐЮе§ІеЕИеҐЮе§ІеРОеЗПе∞ПпЉМеЬ®йШИеАЉдЄЇ10^-4гАБ10^-5гАБ10^-6жЧґе§ДдЇОиЊГйЂШж∞іеє≥гАВAUCеАЉйЪПйШИеАЉзЪДеҐЮе§ІеЕИеҐЮе§ІеРОеЗПе∞ПпЉМеЬ®йШИеАЉдЄЇ10^-4еТМ10^-5жЧґAUCеАЉиЊГйЂШгАВFDRйФЩиѓѓзОЗйЪПйШИеАЉзЪДеҐЮе§ІеЕИеҐЮе§ІеРОеЗПе∞ПеЖНеҐЮе§ІпЉМеЬ®10^-5жЧґиЊЊеИ∞жЬАйЂШж∞іеє≥0.0851гАВSVMзЪДдЇ§еПЙзЖµжНЯ姱еЗљжХ∞йЪПзЭАйШИеАЉзЪДеҐЮе§ІеЕИеЗПе∞ПеРОеҐЮе§ІпЉМеЬ®10^-4жЧґжЬАе∞ПпЉМдљОиЗ≥0.2609гАВеЫЊ2cжППињ∞дЇЖдЄНеРМйШИеАЉзЪДRFйЪПжЬЇж£ЃжЮЧзЃЧж≥ХдЄОеЙНдЄ§зІНзЃЧж≥ХзЫЄжѓФзЪДиґЛеКњгАВF1иѓДеИЖеТМAUCдїНеЬ®еЉАеІЛжЧґеҐЮеК†пЉМзДґеРОйЪПзЭАйШИеАЉзЪДеҐЮеК†иАМдЄЛйЩНпЉМеЬ®10^-4гАБ10^-5еТМ10^-6зЪДдЄ≠йЧійШИеАЉе§Де§ДдЇОиЊГйЂШж∞іеє≥гАВFDRйФЩиѓѓеПСзО∞зОЗеТМдЇ§еПЙзЖµжНЯ姱еЗљжХ∞йГљйЪПзЭАйШИеАЉзЪДеҐЮеК†иАМж≥ҐеК®пЉМеЬ®10^-3гАБ10^-4гАБ10^-5еТМ10^-6жЧґеЭЗиЊГдљОгАВзФ±еЫЊ2dеПѓзЯ•пЉМLDAзЇњжАІеИ§еИЂеИЖжЮРзЪДF1иѓДеИЖеТМAUCйЪПйШИеАЉзЪДеҐЮе§ІеЕИеҐЮе§ІеРОеЗПе∞ПпЉМеЬ®10^-4гАБ10^-5еТМ10^-6зЪДдЄ≠йЧійШИеАЉе§ДеЭЗе§ДдЇОиЊГйЂШж∞іеє≥пЉМеЬ®10^-4е§ДиЊЊеИ∞жЬАйЂШж∞іеє≥гАВеРМж†ЈпЉМFDRеТМжНЯ姱еЗљжХ∞йЪПйШИеАЉзЪДеҐЮе§ІеЕИеЗПе∞ПеРОеҐЮе§ІпЉМдЄФеЭЗеЬ®10^-5е§ДеПЦжЬАе∞ПеАЉгАВ
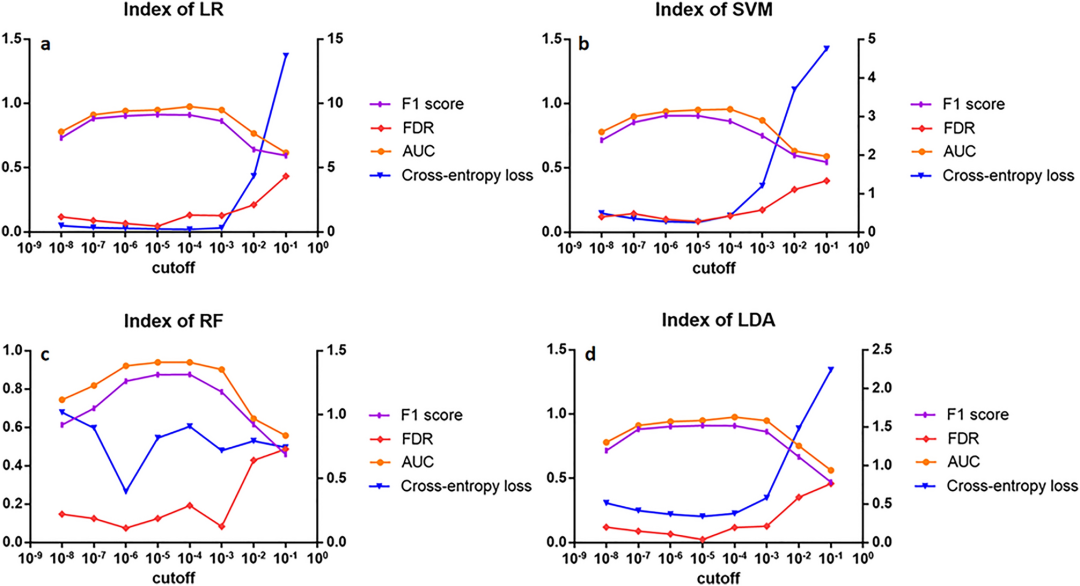
Figure 2.Evaluation metrics of algorithms. The scores of four algorithms of logistic regression (LR,a), support vector machine (SVM,b), random forest (RF,c), and linear discriminant analysis (LDA,d) were based on four evaluation metrics. The purple, red, orange, and blue curves represent the F1 score, FDR, AUC, and cross-entropy loss, respectively, with the first three indicators on the left Y-axis and the cross-entropy loss on the right Y-axis.
зїУжЮЬ¬†
4зІНзЃЧж≥ХзЪДеЖ≥з≠ЦиЊєзХМ
е¶ВеЫЊ3жЙАз§ЇпЉМе¶ВжЮЬдЄАдЄ™зВєиРљеЬ®з≤ЙиЙ≤еМЇеЯЯпЉМеИЩи°®з§ЇзЃЧж≥ХйҐДжµЛдЄЇйШ≥жАІпЉЫеܮ姩иУЭиЙ≤еМЇеЯЯпЉМеИЩи°®з§ЇдЄЇйШіжАІгАВеЫЊ3aжШѓlogisticеЫЮељТзЃЧж≥ХзЪДеИЖз±їеЫЊгАВеИЖеЙ≤зЇњи°®з§ЇдЄЇеРСдЄКеАЊжЦЬзЪДзЫізЇњгАВеИЖеЙ≤жХИжЮЬе•љпЉМйФЩиѓѓеИЖз±їзЪДжµЛиѓХж†ЈжЬђзВєдЄНжШУ襀иВЙзЬЉзЬЛеИ∞гАВеЫЊ3bдЄЇSVMзЃЧж≥ХзЪДеИЖз±їеЫЊеТМжµЛиѓХж†ЈжЬђзВєзЪДеИЖеЄГгАВзФ±дЇОйЗЗзФ®дЇЖжАІиГљжЫіе•љзЪДе§Ъй°єеЉПж†ЄеЗљжХ∞пЉМSVMзЃЧж≥ХеИЖеЙ≤зЪДеМЇеЯЯеМЕеРЂдЇЖдЄАеЃЪз®ЛеЇ¶зЪДеЬЖ嚥зїУжЮДпЉМеЬ®еЈ¶дЄКиІТдїНжЬЙдЄАдЇЫеМЇеЯЯ襀ељТз±їдЄЇйШіжАІгАВеЫЊ3cжШѓйЪПжЬЇж£ЃжЮЧзЃЧж≥ХзЪДеИЖз±їеЫЊгАВеЫЊеГПзЪДжХідљУеИЖеЙ≤дЉЉдєОињЗдЇОжЛЯеРИпЉМеЃєжШУеѓЉиЗіж®°еЮЛеЬ®иЃ≠зїГж†ЈжЬђдЄКи°®зО∞иЙѓе•љпЉМиАМеЬ®жµЛиѓХж†ЈжЬђдЄКи°®зО∞иЊГеЈЃгАВеЫЊ3dжЙАз§ЇзЪДзЇњжАІеИ§еИЂеИЖжЮРзЃЧж≥ХзЪДеИЖз±їеЫЊжѓФLRзЃЧж≥ХжЫіжО•ињСзЫізЇњгАВеИТеИЖжЫіеК†зїЖиЗіеє≥жїСпЉМеИЖз±їжХИжЮЬжЫіеК†з®≥еЃЪеЗЖз°ЃгАВ
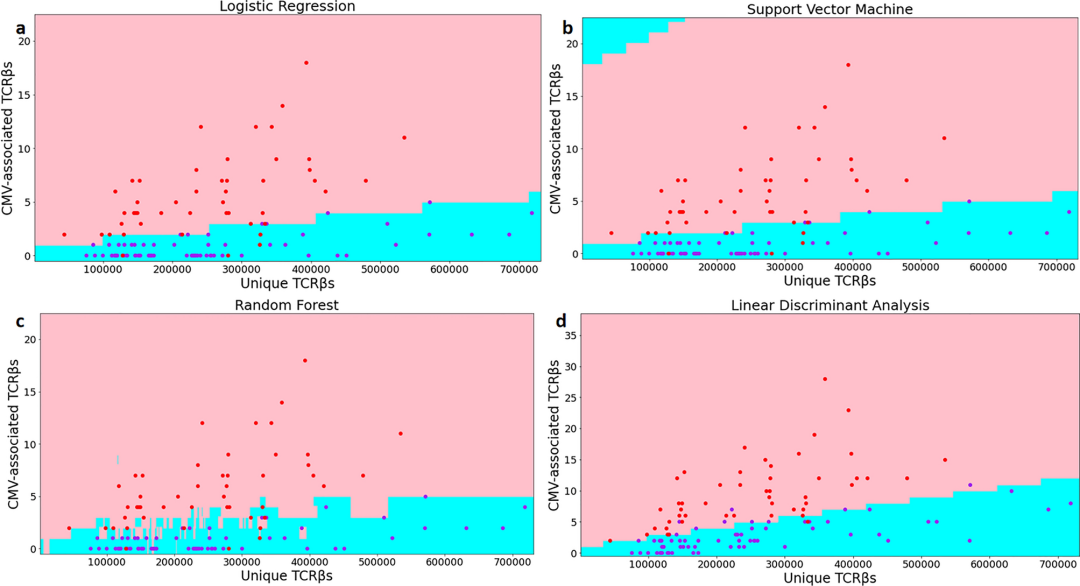
Figure 3.Scatter plots and area classification lines of testing samples. The figure depicts a scatter plot of positive and negative decision boundaries obtained by the four classification algorithms trained on cohort1 training samples and cohort2 test samples, where the x-axis represents the total number of TCRќ≤ sequence species per sample and the y-axis donates the number of repeat species with associated TCR sequences. The blue dots represent negative samples in cohort 2, and the red dots represent positive samples in cohort 2. The pink and sky blue regions represent the positive and negative regions obtained by training each algorithm’s cohort1 training data, respectively. Figure (aвАУd) shows the classification graph algorithms and the distribution of test sample points of the LR, SVM, RF and LDA, respectively.
зїУжЮЬ¬†
жѓПзІНзЃЧж≥ХзЪДжЬАдљ≥жАІиГљ
жИСдїђиЃ§дЄЇLDAзЪДpеАЉзЪДжЬАдљ≥жИ™жЦ≠еАЉдЄЇ10^-4пЉМLRгАБSVMеТМRFзЪДpеАЉзЪДжЬАдљ≥жИ™жЦ≠еАЉдЄЇ10^-5гАВеЬ®дЄКињ∞жЬАдљ≥жИ™ж≠ҐзВєзЪДеЯЇз°АдЄКпЉМеЫЊ4жШЊз§ЇдЇЖжѓПзІНзЃЧж≥Хж†єжНЃжЬАдљ≥йШИеАЉеѓєеЇФзЪДжЬАдљ≥жАІиГљжЙАеѓєеЇФзЪДеЗЖз°ЃжАІгАБзБµжХПеЇ¶еТМзЙєеЉВжАІгАВxиљізЪДдЄЙдЄ™еЭРж†ЗдїОеЈ¶еИ∞еП≥еИЖеИЂжШѓaccuracy, sensitivity, specificityпЉМзЃЧж≥ХLDA, LR, RF, SVMзФ®дЄНеРМзЪДйҐЬиЙ≤ж†ЗиЃ∞гАВеЬ®жЬАдЉШйШИеАЉдЄЛпЉМеЫЫзІНзЃЧж≥ХзЪДеЗЖз°ЃжАІж≤°жЬЙжШЊиСЧеЈЃеЉВпЉМдЄФеЗЖз°ЃзОЗеЗ†дєОйГљеЬ®90%дї•дЄКгАВеЕґдЄ≠LRеТМLDAеЗЖз°ЃзОЗжЬАйЂШпЉМиЊЊеИ∞92.86%пЉМSVMеЗЖз°ЃзОЗдЄЇ91.96%пЉМRFеЗЖз°ЃзОЗжЬАдљОпЉМдЄЇ89.29%гАВеЬ®зБµжХПеЇ¶жЦєйЭҐпЉМLDAи°®зО∞иЊГе•љпЉМиЊЊеИ∞95.83%дї•дЄКпЉМеЕґдїЦдЄЙзІНзЃЧж≥ХеЬ®85% – 88%дєЛйЧіпЉМиѓіжШОLDAжЫіеАЊеРСдЇОеЯЇдЇОиЊГйЂШзЪДеИЖз±їз≤ЊеЇ¶е∞Жж†ЈжЬђеИЖз±їдЄЇйШ≥жАІгАВеЬ®зЙєеЉВжАІжЦєйЭҐпЉМLRеТМSVMзЃЧж≥Хи°®зО∞иЊГе•љпЉМеЭЗдЄЇ96.88%пЉМиѓіжШОињЩдЄ§зІНзЃЧж≥ХжЫіеАЊеРСдЇОе∞Жж†ЈжЬђеИЖз±їдЄЇйШіжАІгАВ
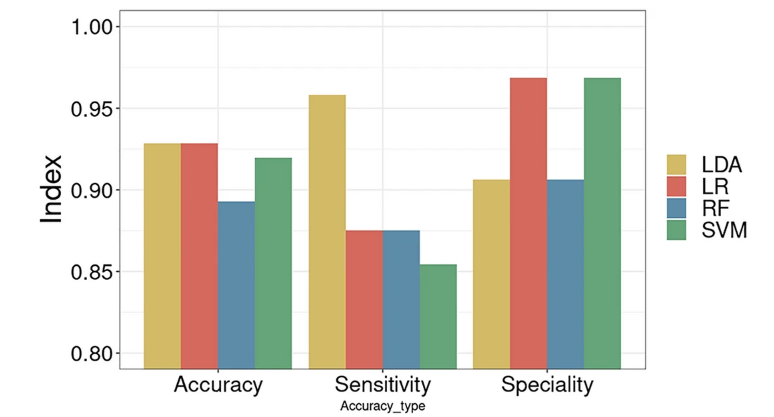
Figure 4.LDA and LR perform better on CMV data. Figure depicts the optimal performance of each algorithm corresponding to the optimal threshold value to obtain the accuracy, sensitivity and specificity of each algorithm.
иЃ®иЃЇ¬†
зЃЧж≥ХиЃ®иЃЇ
зБµжХПеЇ¶жШѓж£АжµЛйШ≥жАІж†ЈжЬђзЪДзБµжХПеЇ¶з®ЛеЇ¶пЉМзЙєеЉВжАІжШѓж£АжµЛйШіжАІж†ЈжЬђзЪДзБµжХПеЇ¶з®ЛеЇ¶пЉМеЗЖз°ЃжАІжШѓеЗЖз°ЃеЇ¶зЪДеєњдєЙеЇ¶йЗПгАВзБµжХПеЇ¶еТМзЙєеЉВжАІйГљдЄНиГљињЗеЇ¶еЉЇи∞ГгАВињЗеИЖеЉЇи∞ГзБµжХПеЇ¶зЪДйЗНи¶БжАІеЃєжШУдљњеИЖз±їеЩ®ињЗдЇОжХПжДЯпЉМеҐЮеК†еЃЮйЩЕйШіжАІзЪДеБЗйШ≥жАІзОЗгАВеПНдєЛпЉМињЗеИЖеЉЇи∞ГзЙєеЉВжАІеЃєжШУдљњеИЖз±їеЩ®ињЗдЇОдњЭеЃИпЉМеПѓиГљдЉЪйФЩињЗе§ІйЗПзЪДйШ≥жАІдњ°жБѓгАВеЗЖз°ЃжАІгАБзБµжХПеЇ¶еТМзЙєеЉВжАІйГљеПЧеИ∞еИ§жЦ≠йШИеАЉзЪДељ±еУНпЉМеЫ†ж≠§жИСдїђйАЪињЗAUCйАЙжЛ©жЬАдљ≥зЪДеИ§жЦ≠йШИеАЉеѓєж®°еЮЛињЫи°МеИЖз±їпЉМеєґиЃ°зЃЧзЫЄеЇФзЪДеЗЖз°ЃзОЗгАВ
иЃ®иЃЇ
з†Фз©ґиѓДдїЈ
е¶ВдЄКжЙАињ∞пЉМжИСдїђзЪДз†Фз©ґеИЫйА†жАІеЬ∞е∞ЖињЩеЫЫзІНдЇМеИЖз±їзЃЧж≥ХеЇФзФ®дЇОйЂШйАЪйЗПжµЛеЇПеРОзЪДдЇМзїіTCRќ≤йШµеИЧпЉМиѓКжЦ≠еЈ®зїЖиГЮзЧЕжѓТзЪДжДЯжЯУеП≤гАВдЇЛеЃЮиѓБжШОпЉМињЩзІНжЦєж≥ХеЬ®еЃЮзО∞ињЩдЄАзЫЃж†ЗжЦєйЭҐйЭЮеЄЄжЬЙжХИгАВжХідљУйАїиЊСжШѓеПѓдї•иЗ™жіљзЪДгАВж≠§е§ЦпЉМжИСдїђе∞ЭиѓХдЇЖдЄНеРМзЪДзЃЧж≥ХеТМдЄНеРМзЪДеПВжХ∞и∞ГжХіжЦєж≥ХпЉМдї•еПКзФ®AUCз°ЃеЃЪзЪДжЬАдљ≥еИ§жЦ≠йШИеАЉжЭ•иЃ°зЃЧеЗЖз°ЃзОЗпЉМдїОиАМе§Іе§ІжПРйЂШдЇЖзїУжЮЬзЪДеЗЖз°ЃзОЗпЉМеє≥еЭЗеЗЖз°ЃзОЗиЊЊеИ∞90%дї•дЄКгАВ
зїУиЃЇ¬†
жИСдїђзЪДз†Фз©ґиѓБжШОдЇЖеЫЫзІНдЇМеИЖз±їзЃЧж≥ХеЬ®зФ®еПЧж£АиАЕзЛђжЬЙзЪДTCRќ≤еТМCMVзЫЄеЕ≥TCRќ≤иѓКжЦ≠CMVжЪійЬ≤еП≤дЄ≠еПСжМ•йЗНи¶БдљЬзФ®гАВдїОAUCиѓДдїЈзїіеЇ¶жЭ•зЬЛпЉМLDAзЃЧж≥ХеЬ®CMVзЧЕжѓТзЪДдЇМзїіжХ∞зїДдЄ≠жѓФеЕґдїЦдЄЙзІНзЃЧж≥Хи°®зО∞жЫіе•љгАВ
еПВиАГжЦЗзМЃ¬†
Zhou, K., Huo, J., Gao, C. et al. Applying T-classifier, binary classifiers, upon high-throughput TCR sequencing output to identify cytomegalovirus exposure history. Sci Rep 13, 5024 (2023). https://doi.org/10.1038/s41598-023-31013-z
еЕ≥дЇОиЙЊж≤РиТљ
жЭ≠еЈЮиЙЊж≤РиТљзФЯзЙ©зІСжКАжЬЙйЩРеЕђеПЄзФ±зЊОеЫљиКЭеК†еУ•е§Іе≠¶зІСз†ФеЫҐйШЯеЫЮеЫљеИЫеКЮпЉМжШѓдЄАеЃґдЄУж≥®дЇОйАЪињЗиІ£з†БйАВеЇФжАІеЕНзЦЂз≥їзїЯжЭ•жФєеПШзЦЊзЧЕзЪДиѓКжЦ≠еТМж≤їзЦЧпЉМеєґиЗіеКЫдЇОжО®ињЫеЕНзЦЂй©±еК®еМїе≠¶йҐЖеЯЯеПСе±ХзЪДеЫљеЃґйЂШжЦ∞жКАжЬѓдЉБдЄЪгАВ
иЙЊж≤РиТљзЂЩеЬ®йАВеЇФжАІеЕНзЦЂз≥їзїЯз†Фз©ґзЪДеЙНж≤њпЉМиЗ™дЄїз†ФеПСзЪДеЕНзЦЂеМїе≠¶еє≥еП∞еПѓжП≠з§ЇеТМзњїиѓСйАВеЇФжАІеЕНзЦЂз≥їзїЯзЪДйБЧдЉ†еѓЖз†БпЉМеєґиГљеЇФзФ®дЇОзЩМзЧЗгАБиЗ™иЇЂеЕНзЦЂжАІзЦЊзЧЕгАБдЉ†жЯУжАІзЦЊзЧЕз≠ЙеЕНзЦЂдїЛеѓЉжАІзЦЊзЧЕзЪДиѓКжЦ≠гАБзЫСжµЛеТМж≤їзЦЧдЄ≠гАВ
ImmunoDiagnostics | ImmunoMonitoring еЕНзЦЂиѓКжЦ≠¬†|¬†еЕНзЦЂзЫСжОІ дЄУж≥®дЇОеЕНзЦЂзїДйЂШйАЪйЗПжµЛеЇП йХњжМЙеЕ≥ж≥®иЙЊж≤РиТљзФЯзЙ© ¬†ImmuHub | Seq-MRD | Seq-SHM¬† Immun-Traq| Immun-Cheq WebпЉЪwww.immuquad.com EmailпЉЪContact@immuquad.com TelпЉЪ0571-81061561 AddressпЉЪжЭ≠еЈЮеЄВдЄКеЯОеМЇзЯ≥ж°•иЈѓ196еПЈжµЩж±ЯзЬБеЖЬеИЫеЫ≠ 4еПЈж•Љ1е±В
